Cascaded revision control strategy
Okay, this isn't rocket-science, and in fact it's not even my idea (heard it on the FLOSS POD about Git). A problem with centralised repository systems such as Subversion (which is used on SourceForge) is that you need network access to do many things, and also to just save your work. You can't do commits to the repo' while on the train, for instance (which is where I do most of my hacking).
One option is to switch to a distributed revision system, such as Git or Mercurial. I may do that some day, but right now is not a good time for me to be learning a new revision system. Plus to have SourceForge host my project in Hg (for instance) means installing it myself and blah-blah-blah. Then there's IDE integration to consider...
I want to have my cake and eat it too.
A very simple compromise is just to have a local SVN repo' on my laptop, to which I commit minor/experimental changes, hacking on bug fixes etc. Then periodically upload only the good changes to the main repo' on my home machine, or to a public SF repo, or wherever (depending on the project). You can employ this same strategy in order to use mixed repo's, if Hg or Git (or LaunchPad) float your boat but your project is in SVN...
Basic idea
The idea is pretty simple. Keep a local SVN repository to which I commit changes. I would have 2 working copies, one form the main/public repo and a 2nd from my private repo. Most hacking would take place in the 2nd working copy, with planned commits back to the main repo via a copy from my 2nd (private) working copy of my private repo to my 1st working copy, then update/commit to public repo:
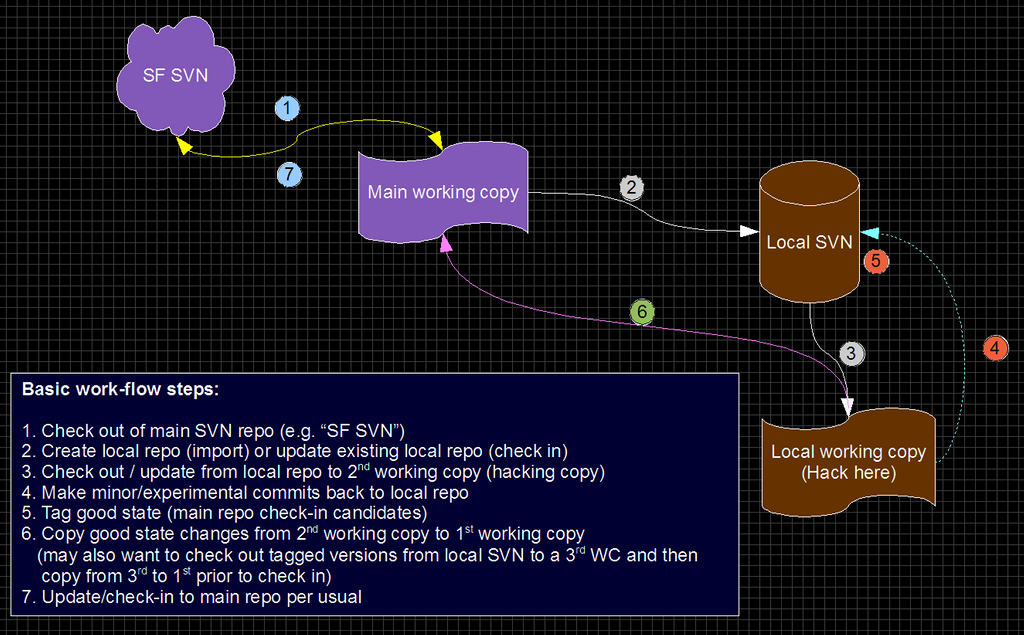
What this achieves
- Local repo to which can commit and revert while offline
- Do not have to make public commits of experimental changes
- Do not have to switch to a distributed revision system (which achieves same aims)
Simple workflow
- Check out of main/public SVN repo
- Create a private repo and import code (or check in)
- Check out of private SVN repo to 2nd working copy
- Make minor/experimental changes in 2nd working copy, commit these to private SVN repo
- Tag good states in private SVN repo (these are public check-in candidates)
- Copy from private 2nd working copy back to 1st working copy (applies your changes in your 1st working copy)
- Update/check-in to main/public repo per usual
Compare/contrast branches
Having a private development stream can also be accomplished by using branches on the public repo. However this does not achieve the aim of being able to commit and revert while offline, or the freedom to experiment without having to publish your false-starts.
Compare/contrast svnsync
Briefly looked at this tool, but it's for mirroring repositories only. It's use case is for distributing query load across multiple servers. However all commits to the target (mirror) repo's must be done exclusively by svnsync, so it does not match my use case: I want to be able to commit locally too.
Tagging "good" commit candidates
Step 5 is interesting: you can tag the local repo when your code reaches a state that is suitable to commit to the main repo. Very useful if you want to commit, but still unable because you're offline. Also a good way to filter out "dumb" commits.
The alternative to tagging good commit candidates would be to roll all the changes together into a single main commit by just checking out of the local SVN back to your 1st working copy at the end. But that would lose some change history. By tagging in local, I can do commits to main in a manner that matches the semantics of the change. That is, first I did A (commented A and tagged A). Then I did B, and so on up to C. Then when commiting back to main, don't just commit C: commit A first and then B, so that the change history is not lost on main repo.
What about updates?
This idea does have a couple of problems with updates from others:
- merging changes from others to the local repo could be an issue. Conflicts might have to be resolved twice? I haven't thought hard about this one yet.
- does not solve the "hide in a hole and get behind" problem, possibly exacerbates it
- could potentially give a false sense of security ("my changes are in the repo, aren't they?"). Potential to forget to commit back to main if always commiting to local...
All of these should be kept in mind, and apply some sense and judgement. The SVN documentation about branches has some good advice. I would add: if you're using a private repo, it might be good to have a public branch to back it as well, so that everyone
knows what's going on, and to assist with the merging, since SVN 1.5 can help if it can see all the changes in seperate branches of one repo, but it can't help when you're trying to merge across two.